Java 服务性能分析用户手册
本文面向 Java 服务负责人、值班响应人员和应用开发人员,说明如何使用 java-profiler 分析 Kubernetes 中 Java 服务的 CPU、Wall Clock 延迟、Java I/O wait、GC pauses、内存分配、锁等待、死锁和线程问题。部署、权限、升级、ClickHouse、Web 代理和平台故障处理见 部署运维管理员手册。如果问题涉及部署、权限、ClickHouse、Web 代理、token 或 collector DaemonSet,请转交平台管理员并引用管理员手册。
真实工作流截图
这些截图来自真实 Kubernetes acceptance 环境,不是 mock UI 状态。保留它们是为了让读者快速理解核心诊断路径,也让维护者有一组可回归对比的 UI 证据。
重新生成截图时,先把真实 Web UI port-forward 到本机,然后从仓库根目录运行:
export REAL_ACCEPTANCE_BASE_URL=http://127.0.0.1:18081
export REAL_ACCEPTANCE_NAMESPACE=java-profiler-qa
export REAL_ACCEPTANCE_SERVICE=jdk17-http-demo
node scripts/capture-doc-screenshots.mjsTarget status
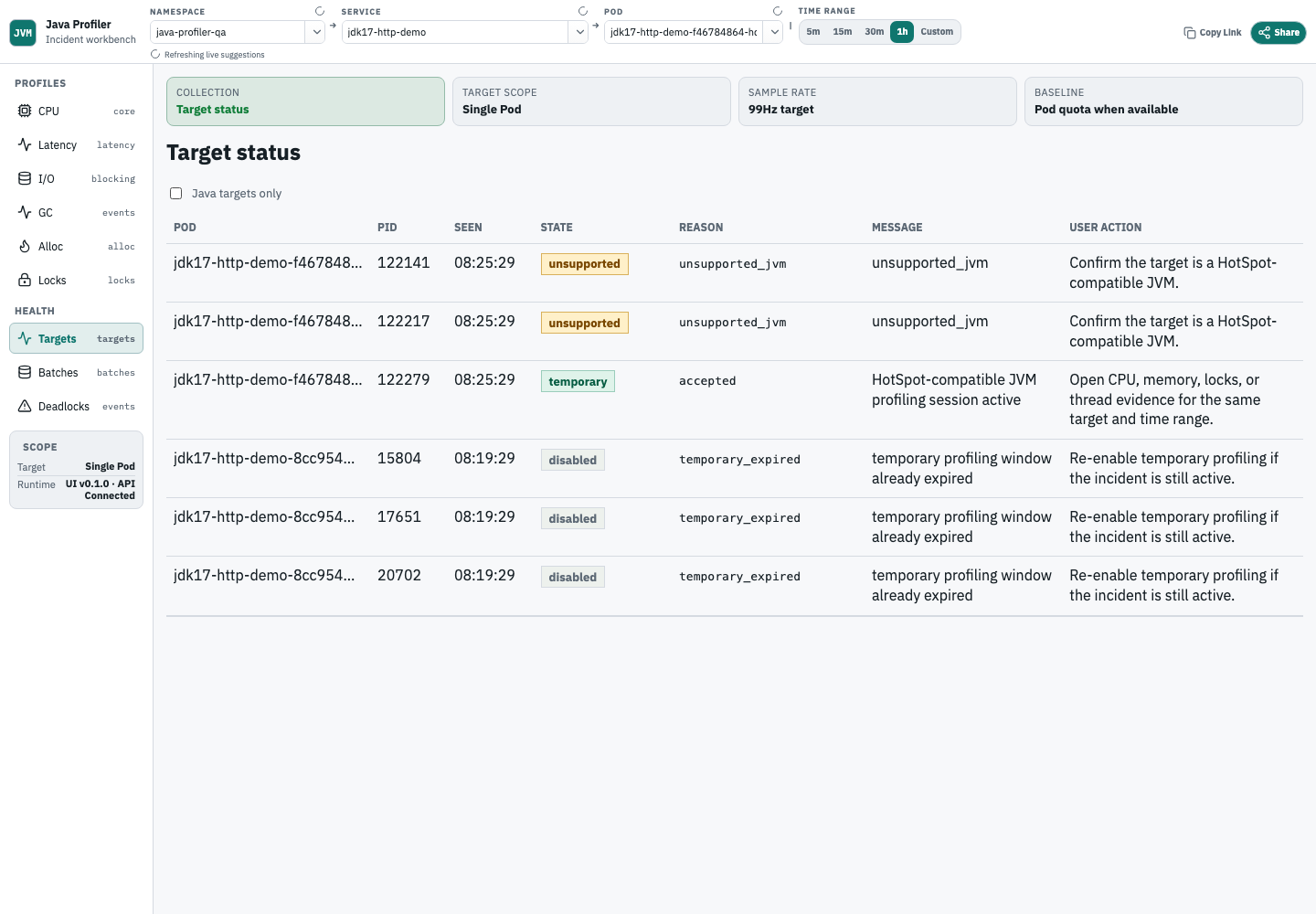
先确认目标 JVM 是否被接受、拒绝或因为 metadata/JVM/runtime 条件而没有数据。
Profile evidence guidance
CPU、Wall Clock、I/O wait、allocation、GC correlation 和 lock 视图在当前 profile 没有 samples 时会显示 Profile evidence status 提示。这个提示不是严格验收里的真实 profile 数据,它只说明下一步该查哪里:
profiling_disabled:目标存在,但 profiling metadata 禁用了采集。temporary_expired:临时 profiling 窗口已经过期。no_matching_target:namespace、service、Pod 或时间范围没有匹配到 Java profiling target。ingestion_gap:aggregate ingestion health 中有 rejected、retryable、dropped 或 truncated profile batches。no_samples_in_range:target 和 ingestion evidence 存在,但当前 scope 和时间范围没有 samples。
用它决定是修 metadata、换目标、扩大时间范围,还是检查 ingestion。不要把可解释空状态当成 strict acceptance 的非空 profile evidence。
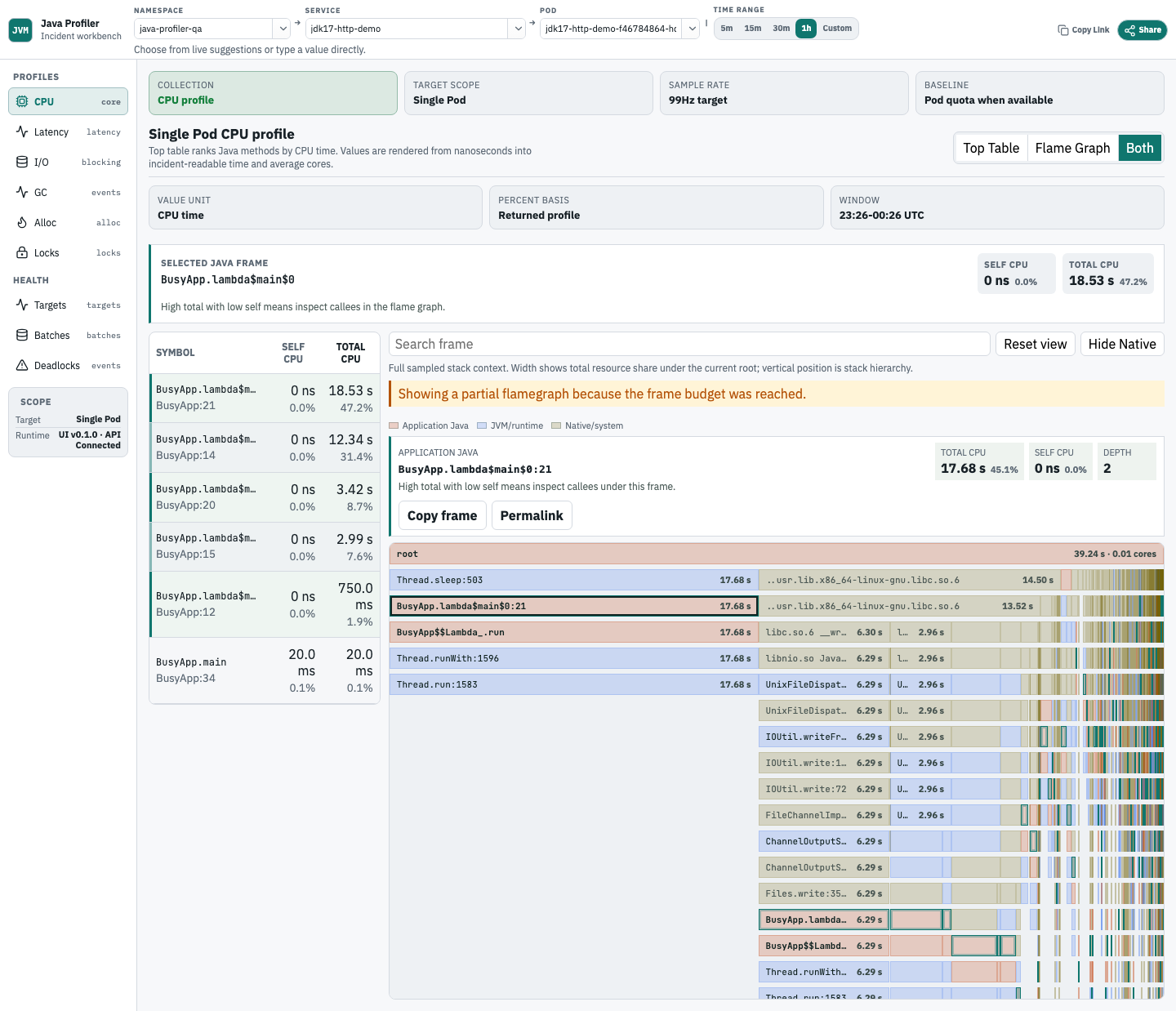
CPU profile analysis
CPU 视图把 Top Table、Flame Graph、选中 frame 详情、Self/Total CPU 语义和 Java frame 分类放在同一个真实服务诊断流里。
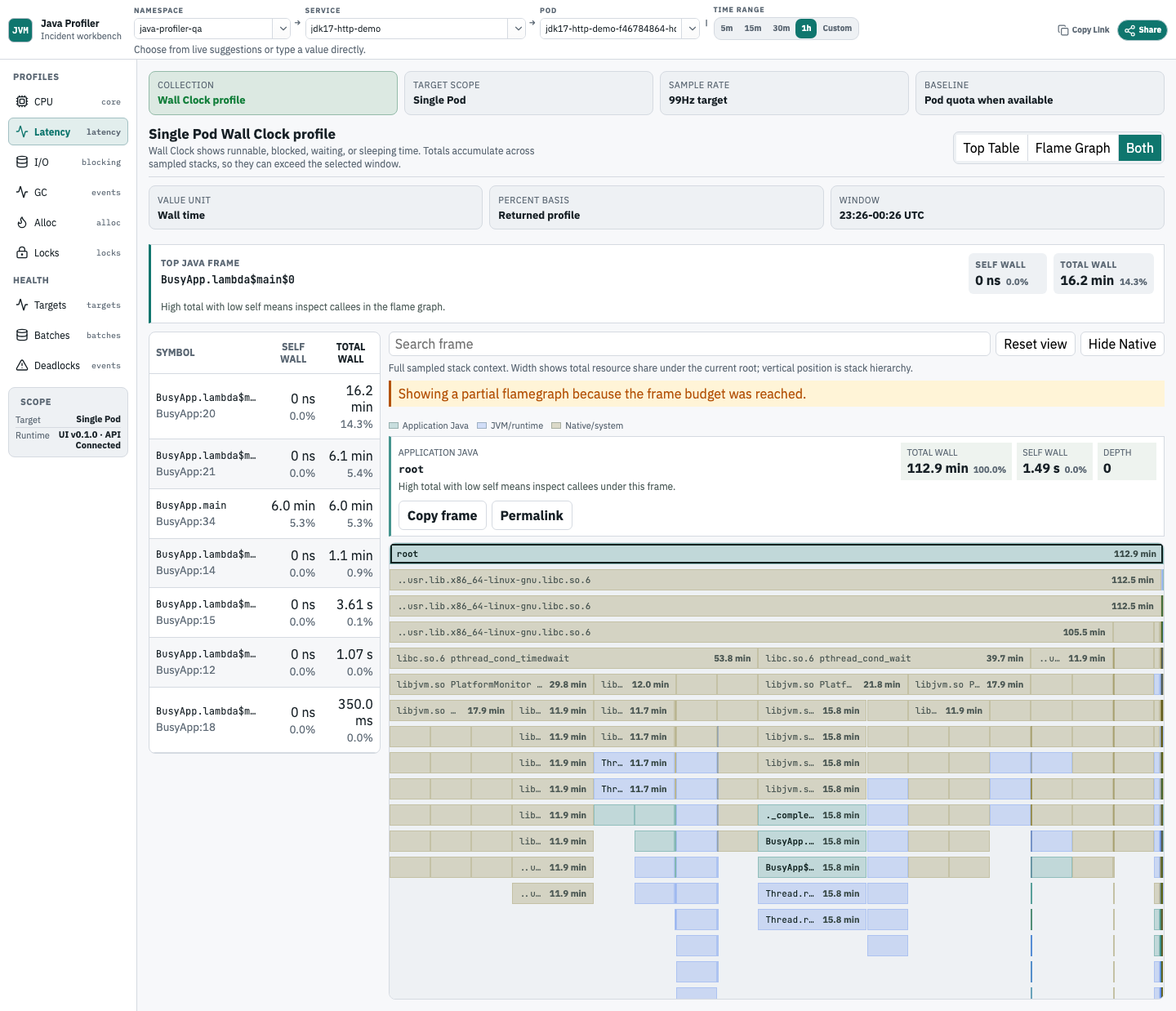
Wall Clock latency
Wall Clock 视图用于分析 CPU 无法解释的延迟。它展示 Java 栈在 runnable、blocked、waiting、sleeping 或 I/O 路径上的墙上时间。
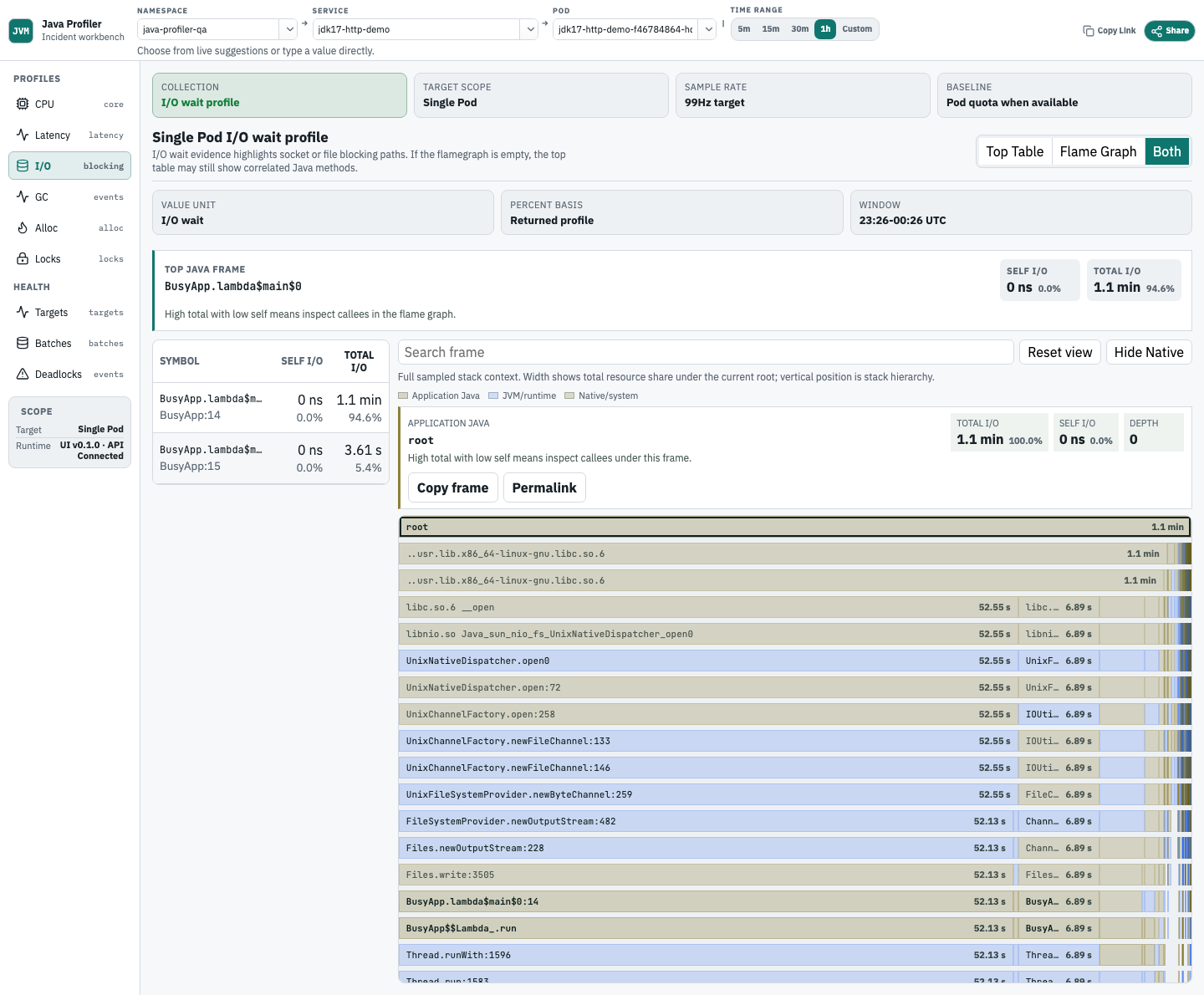
Java I/O wait
I/O wait 视图用于定位 socket、文件或 Java 客户端阻塞路径。只有采集到的 JVM/JFR 栈能保留 Java ownership 时,才把它呈现为 Java I/O wait evidence。
GC pauses
GC 视图把 JVM GC event evidence 与同一时间窗口内的 allocation profile 放在一起,帮助判断暂停是否与对象分配压力相关。
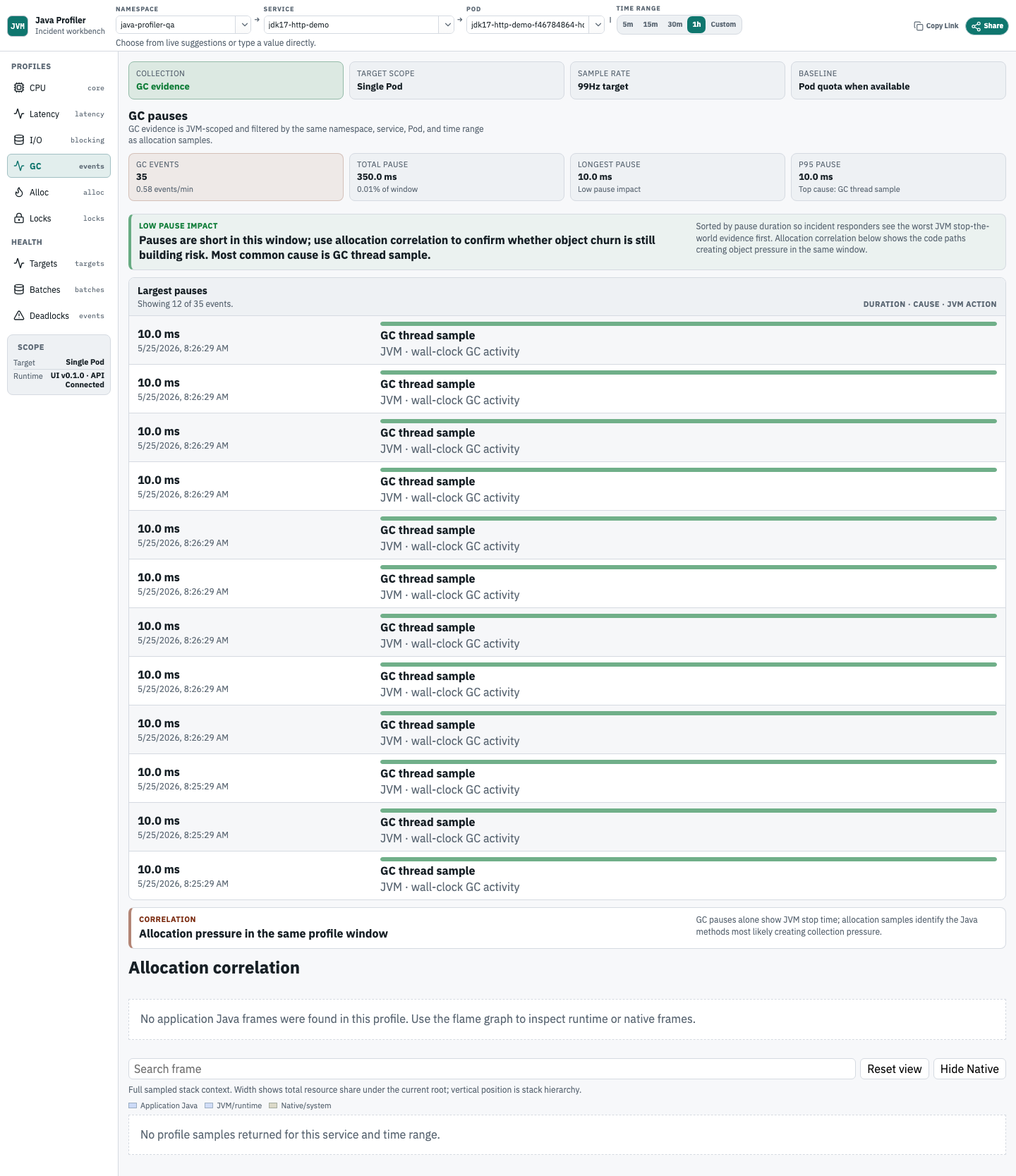
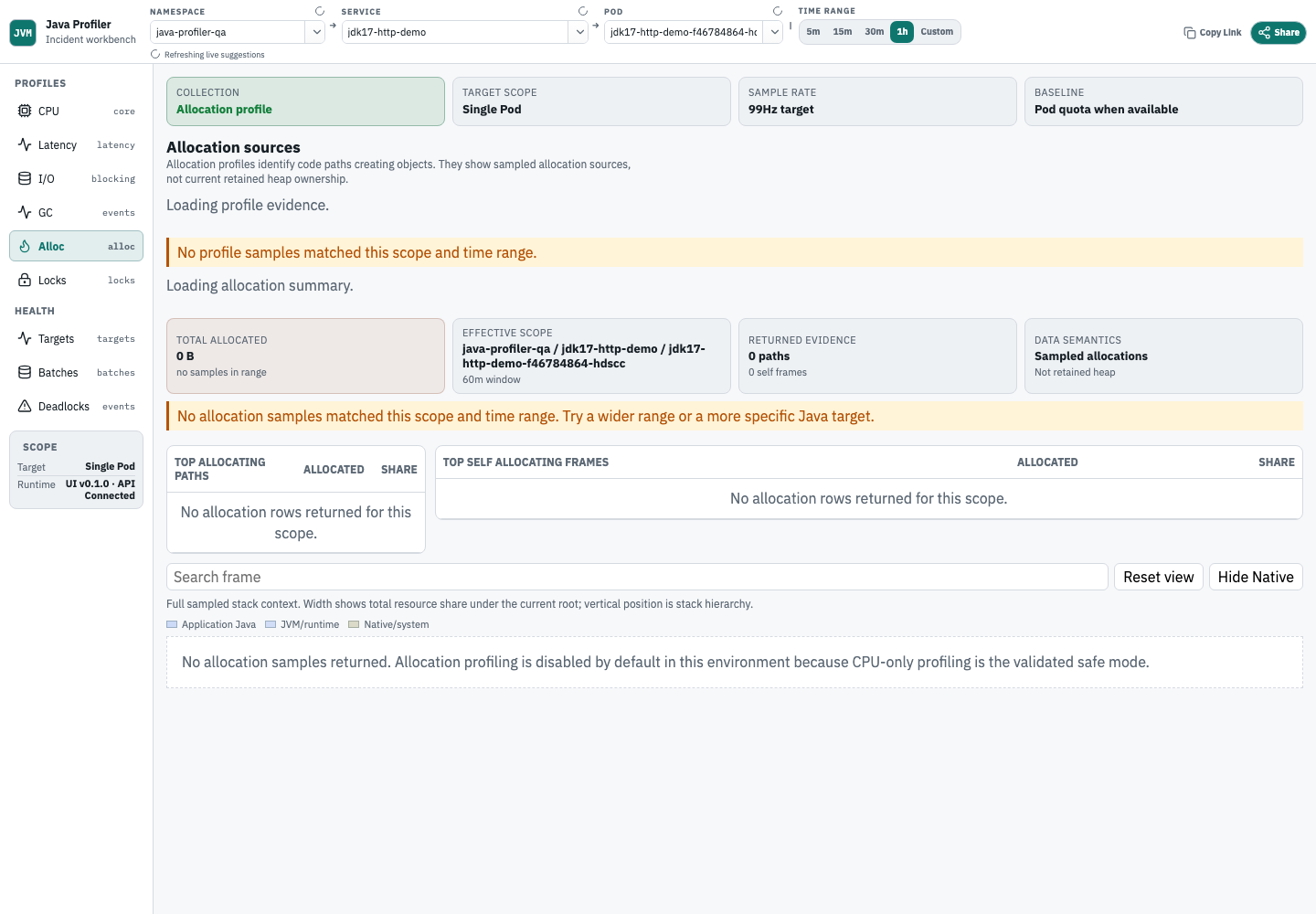
Allocation pressure
分配压力视图用于分析 heap usage、allocation rate 或 GC pressure 上升时的对象创建路径。先读 Allocation Summary,再沿调用栈往下找真正触发分配的代码路径。
- Allocation Summary 展示 total sampled allocation、effective scope、returned path/self-frame counts、insight categories 和 partial-result limits。
- Top allocating paths 按 total allocated bytes 排名 leaf allocation paths。
- Top self allocating frames 排名直接归因到该 frame 的 allocation。
- allocation profile 会展示在所选 service 和时间范围内的对象创建位置。
- 先用 flame graph 查看完整 sampled stack context,再判断哪条调用路径最可疑。
- 最新的 allocation 验收截图展示的是当前的宽布局、Allocation Summary、Top allocating paths、Top self allocating frames 和 flamegraph context。
- allocation 空状态会区分 disabled profiling、target 不匹配、ingestion gap、unsupported runtime、缺失 stack frames,以及当前范围没有 samples。
- namespace-only Allocation Summary 查询限制为 30 分钟;选择 service 或 Pod,或缩短时间范围。所有 allocation summary 查询仍受 7 天 retention 限制。
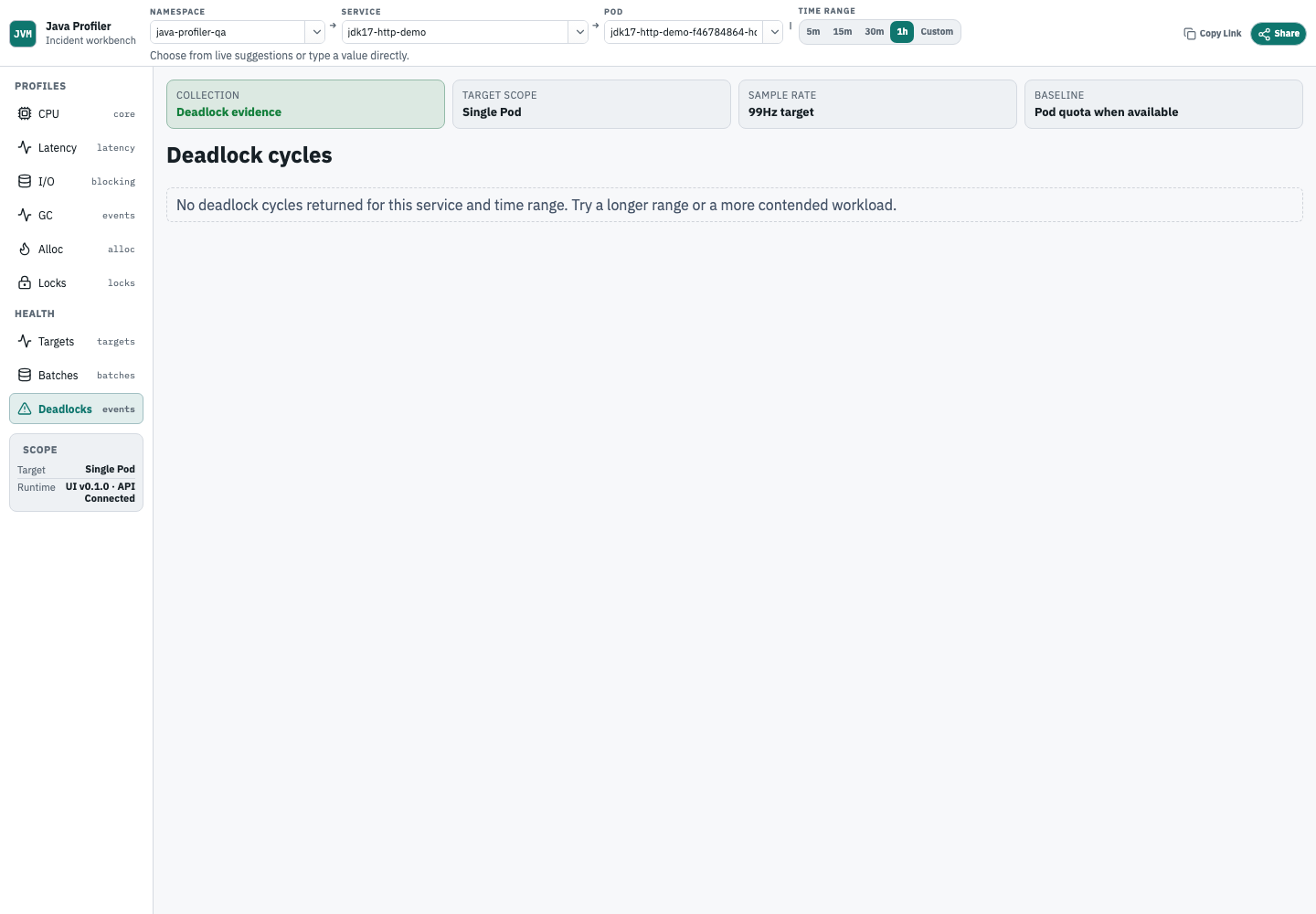
Deadlock diagnosis
死锁视图用于确认选定服务和时间范围内是否有 cycle 证据;真实运行也可能呈现经过验证的空状态。
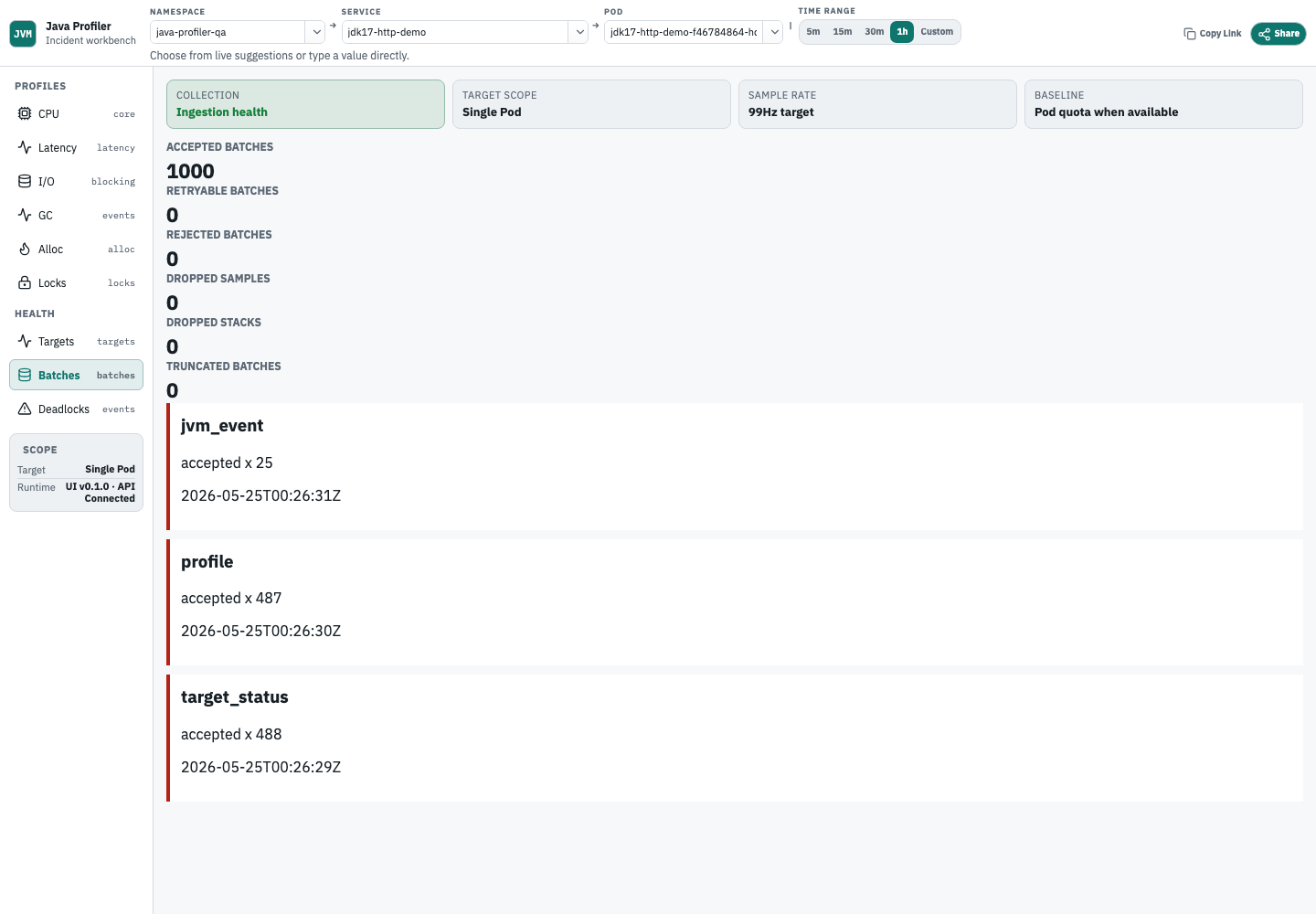
Ingestion health
Ingestion health 用 accepted/rejected/dropped payload 证据闭环 collector 到 backend 的上传和入库路径。
你能用它回答什么
java-profiler 第一版本聚焦 HotSpot 兼容 Java 服务:
- 哪些 Java 调用栈消耗 CPU。
- 哪些调用栈出现 Wall Clock 延迟。
- 哪些 Java socket 或文件路径产生 I/O wait。
- 哪些 GC pause 与 allocation pressure 相关。
- 哪些调用栈分配对象或分配字节最多。
- 哪些锁路径产生等待或竞争。
- 哪些线程处于死锁、阻塞、等待或忙碌状态。
- 目标为什么没有数据:未启用、不兼容、冲突、attach 失败、上传失败或存储失败。
它不是通用观测平台。日志、分布式追踪、Prometheus 指标趋势、告警和服务拓扑仍然从现有观测系统进入。java-profiler 提供的是同一服务、同一时间范围内的 Java 栈证据。
使用前确认
使用前确认:
- 平台管理员已经部署 collector、backend、Web UI 和 ClickHouse。
- 你有权限访问目标 namespace 或 service 的 profiling 数据。
- 目标服务运行在 Kubernetes 中。
- 目标 JVM 是 HotSpot 兼容实现。
- 目标服务已通过
java-profiler.io/*metadata 显式启用 profiling,或你有权限临时启用。
如果 UI 没有数据,先看 status,不要直接判断“没有性能问题”。
启用 profiling
Profiling 默认关闭。你需要在目标 Pod 或 workload Pod template 上添加 annotation 或 label。annotation 与 label 使用相同键名;如果两者都存在,以 annotation 为准。
只有在你拥有该 workload 的变更权限且已获得生产采集批准时,才应直接修改 profiling metadata。否则请通过平台管理员或既有 GitOps/变更流程申请临时 profiling;申请信息见本手册“无法自行启用 profiling 时”。
选择模式
| 模式 | 适用情境 | 建议 |
|---|---|---|
temporary | 线上事件、临时复现、单次排查 | 默认优先选择,必须设置 profile-duration。 |
continuous | 核心服务、长期高流量服务、需要 7 天内随时回溯 | 需要服务 owner 同意长期采集和访问控制。 |
profile-disabled / disabled | 事件结束、止血、明确不采集 | 优先使用 profile-disabled: "true" 止血;合同也允许 profile-mode: disabled。 |
模式选择决策表
| 情况 | 推荐模式 | 原因 |
|---|---|---|
| 正在处理线上事件 | temporary 10 到 15 分钟 | 控制开销,同时捕获现场。 |
| 核心服务长期高流量 | continuous | 需要 7 天内可回溯栈证据。 |
| 只有单个 Pod 异常 | 对该 Pod 使用 temporary | 避免混入其他副本。 |
| 刚上线新版本,需要观察风险 | temporary 30 分钟,或经批准使用 continuous | 取决于风险窗口和服务重要性。 |
| 服务包含敏感业务路径 | 优先 temporary,共享证据时脱敏 | 降低长期暴露面。 |
| 不确定是否可采 | temporary 5 分钟 smoke test | 先验证 status 和 ingestion。 |
临时 profiling
适合排查一次事件。临时模式到期后自动停止。
metadata:
annotations:
java-profiler.io/profile-mode: temporary
java-profiler.io/profile-disabled: "false"
java-profiler.io/profile-duration: 10m
java-profiler.io/startup-delay: 0s
java-profiler.io/snapshot-interval: 10s当前临时窗口按目标 Pod/JVM 的生命周期判断。对已经运行很久的 Pod 直接添加 10m temporary metadata,可能立即显示 temporary_expired;更稳妥的做法是在 workload Pod template 上添加 metadata 后滚动重启,或按管理员确认的方式重开目标 Pod。重复验收时可以添加一次性 annotation,例如 java-profiler.io/acceptance-run: "20260516225619",强制 Deployment 滚动出新的窗口。
临时模式可以短时间提高线程快照频率,但不要长期运行高频快照。
真实 workload smoke test
对线上或准线上 workload 第一次启用真实 async-profiler attach 时,先做短窗口 smoke test。平台管理员应把 collector/backend/UI 指向单个 namespace/service,保存 UI 截图、Playwright 视频、ClickHouse 计数、collector/backend 日志,以及目标 Pod 的前后 restart count。若目标服务在窗口内出现新重启,应先停止 profiling 并排查 attach 安全性,不要继续扩大采集范围。
持续 profiling
适合核心服务保留最近 7 天内的栈证据。
metadata:
annotations:
java-profiler.io/profile-mode: continuous
java-profiler.io/profile-disabled: "false"
java-profiler.io/startup-delay: 30s
java-profiler.io/snapshot-interval: 5m持续 profiling 不是无限保存。所有采集数据仍然不超过 7 天 retention。
停止 profiling
metadata:
annotations:
java-profiler.io/profile-disabled: "true"事件结束后应移除临时 annotation,或保留显式禁用作为止血控制。后续重新启用时,必须删除旧的 profile-disabled: "true",或在 Pod template 上显式设置 profile-disabled: "false";只改 profile-mode 不会覆盖禁用标记。
控制字段
| 字段 | 示例 | 说明 |
|---|---|---|
java-profiler.io/profile-mode | temporary, continuous, disabled | 开启临时、持续或禁用 profiling。 |
java-profiler.io/profile-disabled | "true" | 强制禁用,优先级高于 profile-mode。truthy 值包括 1, true, yes, enabled, on。 |
java-profiler.io/profile-duration | 10m, 1h | 临时 profiling 持续时间。临时模式必填。 |
java-profiler.io/startup-delay | 0s, 30s | 新发现 JVM 启动后等待多久再开始 profiling。 |
java-profiler.io/snapshot-interval | 10s, 5m | 线程快照间隔。临时排障可短时间缩短。 |
时间字段使用 Go duration 格式,例如 30s、10m、1h。
控制字段和 status reason 的稳定合同由平台维护,见 profiling contracts;本手册只解释服务 owner 如何使用这些字段。
无法自行启用 profiling 时
如果你没有权限修改 workload metadata,或目标服务属于敏感生产范围,请向平台管理员提交一次性申请:
Namespace:
Service:
Pod / workload:
Incident window:
Requested mode and duration:
Reason:
Urgency:
Owner / approver:管理员应通过受控变更路径添加 java-profiler.io/* metadata。不要通过临时手工 patch 绕过团队的生产变更规则。
按症状选择入口
紧急排查时先按症状进入对应视图:
| 症状 | 先看 | 再看 |
|---|---|---|
| CPU 高 | status | cpu |
| GC 压力高或 allocation rate 高 | status | memory |
| 请求卡住或线程池耗尽 | status | locks、threads |
| 疑似死锁 | status | deadlocks |
| UI 没数据 | status | ingestion |
| 只有某个 Pod 异常 | status | 缩小到 Pod、container 或 JVM |
| rollout 后行为变化 | status | 按 Pod 和 JVM start time 分开查询 |
常见误判速查
| 不要这样做 | 正确做法 |
|---|---|
| 空 flamegraph = 没有热点 | 先确认 status、ingestion 和时间范围。 |
| accepted = 已经有 profile 数据 | accepted 只说明目标可采,非空 profile 才说明数据链路可用。 |
| allocation 高 = retained heap 高 | allocation 只说明分配来源。 |
| RUNNABLE = 正在消耗 CPU | RUNNABLE 是线程状态,需要结合 CPU profile。 |
| 选中 Top Table 行 = 直接过滤成单行图 | 默认不是。选中应高亮匹配帧并显示详情;搜索是单独动作。 |
| 多副本 service 直接混看 | 先确认是否只有某个 Pod 异常。 |
| 发布窗口混合新旧 Pod | 用 Pod、PID、JVM start time 分开看。 |
5 分钟应急流程
- 记录 namespace、service、Pod 和问题时间范围。
- 打开 UI,选择相同 namespace、service 和时间范围。
- 先打开
status。 - 如果没有权限启用 profiling,把 namespace、service、Pod 和时间范围发给服务 owner 或平台管理员。
- 如果 UI 无权访问目标 namespace,不要申请全集群权限;申请对应 namespace 或 service 的最小访问权限。
- 如果目标不是 accepted,按 reason 处理;需要权限、attach 或平台问题时联系管理员。
- 如果目标 accepted,按症状进入
cpu、memory、locks、deadlocks或线程证据;accepted 只说明控制面允许采集,不等于已经有 profile 数据。 - 如果视图为空,打开
ingestion判断上传、存储或 retention 问题,并确认对应时间窗口有 accepted profile batch。 - 记录 top stack、thread evidence、target status 和 ingestion health。
- 事件结束后停止 temporary profiling 或确认 continuous 是否仍需要保留。
UI 使用顺序
进入 Java Profiling UI 后:
- 选择 namespace。
- 选择 service。
- 选择时间范围。
- 先打开
status。 - 如果同一服务下有多个 Pod 或 JVM,先用
status表中的 Pod、PID、Seen 和 Reason 缩小到具体目标。 - 状态正常后,再看
cpu、memory、locks、deadlocks或线程证据。 - 如果数据为空,打开
ingestion判断上传和存储是否正常。
所有诊断视图共享同一组选择器。发生 rollout、重启或扩缩容时,要核对 Pod、PID 和 JVM start time,避免把旧实例、新实例或无关副本混在一起解释。
页面区域解读
Service diagnosis 是服务级诊断页面。它把同一个 namespace、service、Pod 和时间范围下的证据放在一起,便于从“目标是否可采”切换到 CPU、内存分配、锁、死锁和 ingestion 链路。
页面左侧竖栏提供主视图快捷入口,分别进入 status、cpu、wall、io、gc、memory、locks、deadlocks 和 ingestion。它不是搜索框,也不是筛选器;真正的查询条件在页面顶部的上下文条里。
顶部上下文条显示当前查询条件:
Namespace:当前命名空间。截图示例是java-profiler-qa。Service:当前服务。截图示例是jdk17-http-demo。Range:当前分析时间范围。截图示例是Last 1h。UTC:当前时间显示时区。跨地区协作时,记录事件时间时要同时写明时区;本界面固定以 UTC 呈现时间戳。
上下文条下方的说明强调:Prometheus 仍然负责指标趋势图;本 UI 只展示 profiles、线程证据、目标状态和 ingestion health。也就是说,先用现有监控确认“CPU 高、GC 高、延迟高”这类症状,再回到本页面找 Java 栈证据。
顶部标签页含义:
| 标签 | 用途 | 什么时候打开 |
|---|---|---|
Cpu | 查看 CPU profile flamegraph。 | CPU 高、线程忙、业务路径耗时异常。 |
Wall Clock | 查看 Java stack wall time。 | 延迟高但 CPU 不高、线程 waiting/sleeping/blocking。 |
I/O | 查看 Java socket/file blocking paths。 | RPC、文件、网络或存储调用阻塞。 |
GC | 查看 GC pause event,并关联 allocation profile。 | GC 时间、暂停或 allocation pressure 异常。 |
Memory | 查看 allocation bytes、allocation objects 和 top allocating stacks。 | GC 压力、allocation rate 或对象创建异常。 |
Locks | 查看 lock wait 或 contention profile。 | 请求卡住、线程 BLOCKED、锁竞争。 |
Deadlocks | 查看 JVM 结构化死锁事件。 | 疑似死锁或线程永久互等。 |
Status | 查看每个目标 JVM 是否可采、为什么不可采、用户下一步动作。 | 所有排查都先打开。 |
Ingestion | 查看 collector 上传、backend 接受、ClickHouse 写入和丢弃/拒绝状态。 | profile 或线程证据为空、数据不完整或怀疑链路问题。 |
Status 标签页中的 Target status 表格逐行表示一个目标 JVM 或一次目标状态记录。截图中的关键列按如下方式阅读:
| 列 | 含义 | 解读方式 |
|---|---|---|
Pod | 目标 Pod 名。长名称会截断,排查时应结合完整 Pod 名或 hover/title 信息记录。 | |
PID | 目标 JVM 进程 ID。PID 可能复用,发布或重启窗口内不要只靠 PID 判断身份。 | |
Seen | backend 看到该状态距当前查询时间的时间差。越新越能代表当前状态。 | |
State | collector 对目标的采集状态,例如 temporary、disabled、unsupported。 | |
Reason | 状态原因代码,例如 accepted、disabled_by_metadata、unsupported_jvm。它决定下一步动作。 | |
Message | 面向用户的简短状态说明。它帮助确认 reason 是否符合预期。 | |
User action | 推荐处理动作。优先按这一列处理,再进入 profile 视图。 |
对截图中的三类状态,可以这样解读:
State=temporary且Reason=accepted:该 HotSpot 兼容 JVM 的临时 profiling 已生效,可以进入Cpu、Memory、Locks或线程证据查看同一目标和时间范围内的数据。State=disabled且Reason=disabled_by_metadata:profiling 被 metadata 禁用,或没有启用所需 metadata。需要添加 profiling metadata,或确认显式禁用是预期行为。State=unsupported且Reason=unsupported_jvm:collector 判断该 JVM 不适合当前 v1 HotSpot profiling。先确认它是否为业务 JVM、是否 HotSpot 兼容、是否选错 container 或 PID。
同一服务同时出现 temporary、disabled 和 unsupported 并不矛盾。多副本、重启、sidecar、多 Java 进程或不同 Pod metadata 都可能让同一 service 下有多种状态。排查时先缩小到异常 Pod 和 JVM,再解释 profile 数据。
理解目标状态
status 是第一入口。常见 reason:
| reason | 含义 | 你的动作 |
|---|---|---|
accepted | 目标可被采集。 | 进入 CPU、memory、locks 或线程证据。 |
disabled_by_metadata | 没有启用 metadata,或被显式禁用。 | 添加 profiling metadata,或确认禁用符合预期。 |
temporary_expired | 临时窗口已过期。 | 如事件仍在发生,重新开启临时 profiling。 |
invalid_duration | duration 配置错误。 | 修正为 10m、1h、30s 这类格式。 |
unsupported_jvm | JVM 不兼容 HotSpot,或不是目标业务 JVM。 | 确认 JVM 类型、Pod 内容器和 PID。 |
profiler_conflict | 已有其他 profiler 占用目标 JVM,或前一次运行留下 async-profiler 状态。 | 停止冲突工具;如是验收残留,在管理员确认后滚动目标 Pod 再重试。 |
attach_failed | collector 无法 attach 到 JVM。 | 联系平台管理员检查权限、容器安全策略或 JVM 参数。 |
upload_retryable | 上传暂时失败,可恢复。 | 查看 ingestion,必要时联系管理员。 |
upload_dropped | collector 已丢弃部分批次。 | 该时间窗口证据不完整,联系管理员。 |
storage_rejected | backend 拒绝数据。 | 查看 ingestion,联系管理员排查合同或存储问题。 |
空 flamegraph 不等于没有热点。只有在 target status、ingestion 和时间范围都正确时,空结果才可解释为该窗口没有匹配样本。
分析视图
不同 profile 视图是否有非空数据,取决于当前平台版本、目标 JVM 支持情况、采集窗口和 ingestion 状态;先用 status 和 ingestion 确认可用性。
CPU
cpu flamegraph 展示时间窗口内被采样到的 Java 调用栈。
如果页面同时显示 Top Table 和 flame graph,Top Table 里的 Symbol、Self、Total 应该一起读:
Self和Total都要可见,并且都可以排序。Self说明这个函数自己消耗了多少 CPU。Total说明这个函数加上它的子调用一共消耗了多少 CPU。- 排查瓶颈时,通常先看
Total找到最重的业务入口,再结合Self判断是不是函数本身在烧 CPU。
交互方式要保留完整 stack context:
- 选中表格行时,应高亮完整 flame graph 中的匹配帧,并显示选中帧详情。
- 选中行为不应把主图替换成单行过滤结果。
- 搜索是显式动作;只有用户主动搜索时,才对非匹配帧做高亮或淡化。
- 点击火焰图块进入
focus后,当前块会变成新的根,子树按新的根重新缩放。 Back用于回到上一级 focus,Reset用于回到完整上下文。- 选中帧详情应包含符号、样本、类别,以及
Self/Total的解读。
阅读方式:
- 宽度越大,代表累计 CPU 样本越多。
- 优先看业务方法、序列化、正则、JSON、加密、压缩、数据库客户端、缓存路径。
- CPU profile 是采样证据,不会还原每一次方法调用。
Memory
memory 视图用于 allocation 分析:
- allocation bytes:哪些路径分配字节最多。
- allocation objects:哪些路径创建对象数量最多。
不要把 allocation profile 解读成 retained heap。它不能回答“谁持有对象”“引用根是什么”“哪个对象泄漏”。这类问题需要 heap dump 或 retained-heap 分析。
Locks
locks 视图用于看 lock wait time 或 lock contention count。结合线程快照一起看:
- lock flamegraph 解释时间范围内的锁成本。
- 线程快照解释采样时刻的线程状态。
- 两者指向同一路径时,结论更强。
Deadlocks
deadlocks 展示 JVM 结构化线程数据派生出的死锁事件:
- 涉及线程。
- 等待的锁。
- 锁 owner。
- 阻塞栈帧。
没有 deadlock event 不代表没有慢请求,可能是普通锁等待、IO 等待或线程池耗尽。
Threads
忙线程和慢线程证据可能来自:
- JVM per-thread CPU time。
- RUNNABLE 快照。
- CPU profile 热栈关联。
RUNNABLE 是线程状态,不是 CPU 百分比。UI 若标记为 sampled 或 profile-only,应按采样证据解释。
Ingestion
当 profile 或线程证据为空时,看 ingestion 只为回答三个问题:
- collector 有没有上传数据。
- backend 有没有接受数据。
- 是否出现 retryable、dropped 或 rejected,需要联系管理员。
如果出现 dropped,该时间窗口证据不完整。如果出现 rejected,不要反复重试或继续解释业务问题,先联系管理员排查上传合同或存储问题。
使用案例
案例 1:首次接入一个 Java 服务
适用情境:服务负责人希望让服务具备性能排查能力。
步骤:
- 确认服务是 Kubernetes 中的 HotSpot 兼容 Java 服务。
- 先用 temporary 模式接入 15 分钟。
- 在 UI 选择 namespace、service 和最近 15 到 30 分钟。
- 打开
status,确认目标是accepted或temporary。 - 查看
cpu、memory、locks是否有数据。 - 事件结束后移除临时 annotation 或显式禁用。
预期证据:
status有 Pod、PID、Seen、State、Reason。ingestion能看到 target status 或 profile batch 被接受。
容易误判:
- 只修改 Deployment metadata,没有修改 Pod template。
- 服务无负载时 profile 可能很少,但 status 应该能解释采集状态。
案例 2:持续 profiling 用于核心服务
适用情境:核心高流量服务需要保留最近 7 天内栈证据。
步骤:
- 与团队确认长期采集和访问控制。
- 在 Pod template 上启用
continuous。 - rollout 后打开
status,确认所有 Pod 状态。 - 定期查看
ingestion,确认没有持续 retry 或 dropped batch。 - 遇到事件时直接选择事件时间范围分析。
预期证据:
- 多副本服务的多个 Pod 分别显示状态。
- 最近 7 天内可查询 profile。
容易误判:
- continuous 不代表无限保存。
- profile 是采样证据,不是完整调用日志。
案例 3:CPU 升高
适用情境:监控显示某服务 CPU 峰值。
步骤:
- 从监控记录 namespace、service、Pod 和峰值时间。
- 如未启用 profiling,开启 temporary 10 到 15 分钟。
- 打开
status,确认目标 accepted。 - 打开
cpu,选择峰值时间窗口。 - 查看最宽业务栈和框架栈。
- 记录 top stack、Pod/JVM、时间范围和结论。
预期证据:
- CPU flamegraph 有非 root 栈。
- top stack 能解释 CPU 样本来源。
容易误判:
- 事件已过去才启用 profiling,无法还原过去现场。
- 选错时间范围会看到正常负载。
案例 4:GC 压力或 allocation rate 升高
适用情境:GC 次数、GC 时间或 allocation rate 异常。
步骤:
- 用监控确定时间范围。
- 打开
memory。 - 先看 allocation bytes。
- 如果怀疑小对象风暴,再看 allocation objects。
- 定位集合复制、字符串拼接、JSON 序列化、正则、缓存反序列化等路径。
预期证据:
- allocation flamegraph 能说明分配来源。
- bytes 和 objects 可能指向不同热点。
容易误判:
- allocation 高不等于 retained heap 高。
- 本系统不能直接定位引用根。
案例 5:锁竞争导致请求慢
适用情境:请求延迟升高,线程出现 BLOCKED、WAITING 或 TIMED_WAITING。
步骤:
- temporary 开启 profiling。
- 将
snapshot-interval临时设为10s。 - 打开
locks看 lock delay 或 contention。 - 查看 slow-thread 证据。
- 关注 monitor、park、连接池、缓存锁、日志锁、类加载或单例初始化路径。
预期证据:
- lock flamegraph 集中在少数路径。
- slow-thread 栈与 lock 热点一致。
容易误判:
- 单次线程快照只能说明采样时刻状态。
- RUNNABLE 不一定代表正在消耗 CPU。
案例 6:疑似死锁
适用情境:请求永久卡住、线程池不释放或 JVM 工具提示 deadlock。
步骤:
- 打开
deadlocks。 - 选择问题发生时间范围。
- 查看 deadlock cycle、线程、锁 owner 和 blocking frame。
- 如果没有事件,检查
status和线程快照是否采集成功。 - 如问题仍在发生,提高短时间线程快照频率后再观察。
预期证据:
- deadlock cycle 清楚显示互相等待的线程和锁。
容易误判:
- 没有 deadlock 不代表没有阻塞。
- 死锁超过 retention 后不会保留。
案例 7:线程池耗尽或忙线程
适用情境:队列堆积、请求超时,但 CPU 不一定高。
步骤:
- 查看 busy threads 和 slow threads。
- 有 per-thread CPU time 时优先看精确线程 CPU 证据。
- 没有 per-thread CPU time 时,把 RUNNABLE 快照和 CPU flamegraph 关联。
- 结合线程名、线程池配置、队列长度和下游依赖指标判断。
预期证据:
- busy threads 指向高 CPU 或频繁 RUNNABLE 的线程。
- slow threads 指向阻塞、等待或锁竞争路径。
容易误判:
- 线程池耗尽可能由下游 IO 慢引起,profile 只能提供 Java 栈证据。
案例 8:UI 没有数据
适用情境:CPU、memory、locks 或 deadlocks 页面为空。
步骤:
- 检查 namespace、service、Pod、JVM 和时间范围。
- 打开
status。 - 如果是
disabled_by_metadata,在有权限且获批时通过受控变更路径添加 profiling metadata;否则按“无法自行启用 profiling 时”申请。 - 如果是
temporary_expired,重新开启临时窗口。 - 如果是
unsupported_jvm、profiler_conflict或attach_failed,按 reason 处理。 - 打开
ingestion,检查 retry、dropped、rejected。 - 确认数据是否超过 7 天 retention。
预期证据:
- 空状态能被 status 或 ingestion 解释。
容易误判:
- 空页面不是诊断结论。
案例 9:临时窗口过期
适用情境:status 显示 temporary_expired。
步骤:
- 查看 Seen 时间和 Pod。
- 确认
profile-duration是否已经过期。 - 如果事件仍在发生,重新设置新的 temporary 窗口。
- 如果事件已结束,移除 annotation。
预期证据:
- 新窗口内目标显示为
temporary或accepted。
容易误判:
- 同一 service 可能同时显示旧 Pod expired 和新 Pod accepted。
案例 10:多副本服务排查
适用情境:Deployment 或 StatefulSet 有多个 Pod。
步骤:
- 先按 service 查询
status。 - 如果监控指向某个 Pod,缩小到该 Pod。
- 如果所有 Pod 异常,按 service 级 profile 查共同热点。
- 如果只有单 Pod 异常,对比该 Pod 与其他 Pod 的栈。
- rollout 期间分开看旧 Pod 和新 Pod。
预期证据:
- 每个 Pod 有独立 target status。
- Seen、PID 和 JVM start time 帮助区分实例。
容易误判:
- 多副本混看可能掩盖单实例异常。
案例 11:多容器 Pod 或 sidecar
适用情境:Pod 中有业务容器、sidecar、helper 或多个 Java 进程。
步骤:
- 在
status中查看 container、PID 和 JVM start time。 - 确认目标 Java 进程属于业务容器。
- 如果支持过滤,缩小到目标 container 或 JVM。
- 不要把 sidecar profile 解释为业务服务热点。
预期证据:
- target identity 能区分 Pod、container、PID 和 JVM start time。
容易误判:
- Pod 相同不代表 JVM 相同。
- PID 可复用,必须结合 JVM start time。
案例 12:Pod 重启或发布窗口
适用情境:问题发生时服务正在重启、扩缩容或发布。
步骤:
- 查看 Pod、PID、JVM start time 和 Seen 时间。
- 将 profile 时间范围对齐到具体 Pod 生命周期。
- 发布前后分别查询。
- 对同一 PID 的不同 JVM start time 分开解释。
预期证据:
- 新旧 JVM 具有不同 JVM start time。
容易误判:
- 发布窗口内 profile 可能混合新旧代码路径。
案例 13:unsupported JVM
适用情境:目标显示 unsupported_jvm。
步骤:
- 确认 JVM 分发版和版本。
- 确认是否为 HotSpot 兼容。
- 检查是否为 wrapper、helper 或非业务 Java 进程。
- 如果同一 Pod 有多个 Java 进程,按 PID 区分。
预期证据:
- 业务 JVM 若 HotSpot 兼容,应有自己的状态。
容易误判:
- 一个 Java 进程 unsupported 不代表整个 Pod 都不能分析。
案例 14:profiler 冲突
适用情境:目标显示 profiler_conflict。
步骤:
- 确认是否有人手动运行 async-profiler。
- 检查是否存在其他 profiler 或诊断 agent。
- 停止冲突工具,或决定跳过该 JVM。
- 等待 collector 下一次扫描。
预期证据:
- 冲突解除后状态变为 accepted 或对应启用状态。
容易误判:
- 不要同时对同一 JVM 运行多个 profiler。
案例 15:attach 失败
适用情境:目标显示 attach_failed。
步骤:
- 记录 Pod、container、PID、JVM start time 和 message。
- 联系平台管理员检查 collector 权限、目标容器安全策略和 JVM attach 参数。
- 修复后重新触发扫描或等待下一次扫描。
预期证据:
- 权限或 JVM 参数修复后状态变为 accepted 或其他明确状态。
容易误判:
- attach 失败不是“没有性能问题”,而是采集失败。
案例 16:真实 profile 数据链路确认
适用情境:你需要确认系统不仅能发现目标,还能完成性能分析。
步骤:
- 对 JDK17 demo 或有稳定 CPU、allocation、lock contention 负载的 HotSpot Java 服务启用 profiling。
- 确认
status在当前运行窗口内为 accepted。 - 等待至少一个 profile batch 被 backend accepted。
- 打开
cpu,确认 Top Table 和 flamegraph 都有非 root 栈。 - 打开
memory和locks,确认 allocation 与 lock-delay 都有非空栈。 - 在
cpu里执行搜索、选中 frame、查看详情、Focus、Back、Reset。 - 打开
ingestion,确认 profile batch accepted,且没有 unexplained rejected/dropped/truncated 证据。 - 改变时间范围,确认查询结果随时间窗口变化。
- 如果这是验收而非日常排障,还要保存 ClickHouse sample/stack 行数、TTL、浏览器截图和目标 Pod restart count 前后对比。
预期证据:
- UI 中出现真实方法栈和样本值。
ingestion显示对应 profile batch 被接受。- CPU、allocation、lock-delay 都非空,才能证明核心 profile 链路完整。
容易误判:
- 只有 target status accepted 只能证明控制面可用,不能证明 profile 数据链路完整可用。
- thread snapshot 和 deadlock event 是补充证据;如果本次不是排查线程或死锁,它们为空应记录为 gap,而不是否定 CPU/memory/lock profile 验收。
安全和开销建议
- 默认只对明确需要的 Java 服务启用。
- 事件排查优先使用 temporary,并设置明确 duration。
- 高频线程快照只用于短时间窗口。
- 栈数据可能包含类名、方法名、包名和业务路径,应按生产敏感数据处理。
- 不要把完整 flamegraph、thread dump、stack payload、profile payload、thread snapshot 或 token 粘贴到公开 issue、聊天群或截图中。
- 对外共享时,只保留必要方法名;按组织安全策略脱敏包名、服务名、namespace、Pod 名和业务路径。
- profile 数据不是日志,但仍可能暴露业务流程、内部类名、接口路径或客户相关处理逻辑。
- token、cookie、内部域名、内部 backend/storage 凭据或连接信息不得出现在截图、PR、issue 或聊天记录中。
- 发现 profiler 冲突时,不要同时运行多个 async-profiler 工具采同一个 JVM。
- 采集失败不应被忽略;先读
status和ingestion。
数据保留
所有采集数据保留不超过 7 天:
- profile samples 和 stacks:7 天。
- thread snapshots 和 thread stacks:7 天。
- deadlock events:7 天。
- target status 和 ingestion health:7 天。
- 可选 raw artifact:默认关闭;如启用,最长 24 小时。
超过 retention 后,只能重新采集或使用其他历史证据。Prometheus 指标趋势可能仍存在,但 Java 栈证据不会由本系统长期保存。
历史事件超过 retention
如果事件已经超过 7 天:
- 不要把空结果解释为没有问题。
- 使用 Prometheus、日志、变更记录和业务事件记录回溯时间线。
- 如果问题仍可复现,重新启用 temporary profiling。
- 如果问题不可复现,把缺失 profile 证据记录到复盘结论中。
结果解读边界
| 问题 | 本系统能否回答 | 说明 |
|---|---|---|
| 哪段 Java 代码消耗 CPU | 能 | 使用 CPU flamegraph。 |
| 哪段 Java 代码分配最多 | 能 | 使用 allocation bytes 或 allocation objects。 |
| 哪些锁路径产生等待 | 能 | 使用 lock profile 与 slow-thread 证据。 |
| 是否存在 Java 死锁 | 能 | 使用 deadlock event。 |
| 哪个对象保留了堆内存 | 不能 | 需要 heap dump 或 retained-heap 分析。 |
| 完整还原历史线程执行过程 | 不能 | 线程快照是采样时刻证据。 |
| JVM 指标趋势和告警 | 不在本系统内 | 使用现有 Prometheus 面板。 |
| 非 Java 服务 profiling | 第一版本不支持 | 仅 HotSpot 兼容 Java 服务。 |
术语表
| 术语 | 含义 |
|---|---|
| target | 一个可被发现和采集的 JVM 进程。 |
| target identity | 用于区分目标的身份字段,包括 cluster、namespace、service、pod、container、PID 和 JVM start time。 |
| status | collector 对目标当前采集状态的判断,例如 accepted、disabled、unsupported、attach_failed。 |
| reason | status 的原因,决定用户下一步动作。 |
| accepted | collector 认为目标可采集;它只证明控制面可用,不保证已经有非空 profile。 |
| non-empty profile | 已经有 CPU、allocation 或 lock 样本写入并可查询;这是性能分析数据链路可用的证据。 |
| ingestion | collector 上传数据到 backend,并由 backend 写入 ClickHouse 的过程。 |
| profile batch | 一次 CPU、allocation 或 lock profile 上传批次。 |
| target status batch | collector 上传的一批目标状态。 |
| flamegraph | 用宽度表示样本累计值的调用栈图。 |
| JVM start time | JVM 启动时间,用来区分 PID 复用后的不同 JVM。 |
| retention | 数据最大保留时间。本系统 profile、thread、deadlock、status 和 ingestion 数据不超过 7 天。 |
向平台管理员求助时提供什么
如果需要平台管理员协助,请一次性提供这些信息,避免来回确认:
Namespace:
Service:
Pod:
Container / JVM if known:
Time range:
UI view: status / cpu / memory / locks / deadlocks / ingestion
Status reason:
Ingestion state:
What you expected:
Screenshot or sanitized evidence: redact tokens/cookies/DSN/internal domains/customer identifiers; prefer stack summaries over raw payloads.事件记录模板
Service:
Namespace:
Pod/JVM:
Incident window:
Profiling mode: temporary / continuous
Profile views used: cpu / memory / locks / deadlocks / status / ingestion
Top stack:
Thread evidence:
Target status:
Ingestion health:
Conclusion:
Follow-up:
Profiling stopped at:
Redaction check: no tokens/cookies/DSN/internal domains/customer identifiers/raw payloads.